
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 캐나다 은행계좌 개설
- Normalizing flow
- Docker
- 콘도렌트
- 프라이탁 존버
- 딥러닝
- Generative model
- agnoster폰트깨짐
- 캐나다 TDBAnk
- 캐나다월세
- GAN
- iterm2꾸미기
- 프라이탁
- agnoster폰트꺠짐
- 캐나다 TD 예약
- MachineLearning
- 터미널꾸미기
- DTW
- 머신러닝
- 캐나다 TD 한국인 직원 예약
- agnoster폰트
- 캐나다콘도렌트
- GenerativeModel
- Flow
- iterm2자동완성
- pytorch
- 캐나다 은행 계좌 개설
- 캐나다 TD 한국인 예약
- EATS
- iterm2환경설정
- Today
- Total
TechNOTE
[Murphy ML] 14-1 Kernels 본문
후딱후딱 정리해보도록 하겠다.. ㅜㅠ 어쩌다가 스터디 1번이 걸려서..

14. 1 Introduction
지금까지는 discrete한 fixed size feature vector에 data를 표현할 수 있다고 가정하고 모델을 만들었지만, 그럴 수 없는 경우 (length가 다양한 경우) 에는 이 방법을 사용할 수 없다. 그래서 다음과 같은 방법을 사용하는데,
1. data를 표현하는 Generative model을 가정해서 사용한다
2. data간의 similarity를 표현할 수 있는 kernel 함수를 정해서 사용한다. 이 method는 우리가 처리하는 데이터 x의 내부를 볼필요가 없을 때 사용된다고 한다.
14.2 Kernel function

실수 범위에서 정의되고, k(x, x') ∈ R / x, x′ ∈ X 이고 symmetric이고 non negative인 function으로 정의된다.
14.2.1 RBF Kernels
Squared Exponential Kernel of Gaussian Kernel은 다음과 같이 정의된다.

만약 diagonal covariance를 가지고 있다면 다음과 같이 표현이 가능하다.

각 σj는 각각 dimension에 characteristic length scale로 생각하면 된다. 만약 무한으로 가면 그 corresponding dimension은 무시됨
이는 ARD Kernel 이라고 불린다.
만약 covariance가 spherical하다면 다음과 같은 isotropic kernel이 된다.

여기에서 $\sigma^2$는 bandwith라고 하고, 위의 식은 radial basis function or RBF kernel 이라고 불린다.
14.2.2 Kernels for comparing documents
두 documents 를 비교하기위해 좋은 metric은 무엇일까?
가장 간단하게는, bag of words로 생각해 봐서 xij를 word j가 document i에 나타나는 횟수라고 생각해서 이 document마다 나오는 vector를 가지고 cos similarity를 구하면 된다.
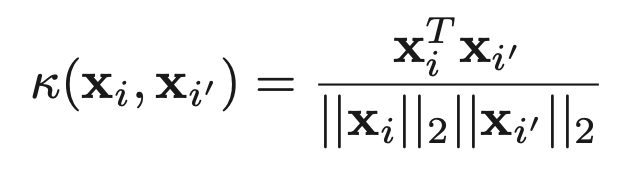
하지만 이렇게하면 문제가 있다..
너무 많이 등장하는 stop word (and, the,,..) 들은 similarity를 측정하는데 좋지 않은 영향을 주고
한 document에 일반적이지 않은 단어가 너무 많이 등장할 시에 측정이 정확하지 않을 수 있다는 것.
따라서, TF-IDF representation을 사용하는데
일단 tf는 count에 log transform을 한 것.

다음은 inverse document frequency인 idf이다. N은 document number이다.

그래서 다음과 같이 곱해서 사용한다.

이제 이 tf-idf score로 cos simiarity를 측정하면 된다!!

잘 된다고 함 저기에 $\phi$ 이게 tf-idf라고 생각하면된다.
14.2.3 Mercer (positive definite) kernels
다음과 같이 정의되는 Gram matrix

어떤 input set에 대해서도 postivie definite를 유지해야 한다. 다음을 만족하는 kernel을 Mercer kernel 또는 postivie definite kernel 이라고 하는데 Mercer's theorem에 의해서 중요성을 입증할 수 있다고 한다. positive definite이므로 eigenvector decomposition을 해 본다면,


따라서 eginevector들로 implicit하게 정의되는 feature vector의 곱으로 kernel matrix의 값을 계산할 수 있게 된다. 다시 말해서, Mercer kernel 인 경우x ∈ X to RD 로 맵핑하는 function $\phi$ 가 존재한다고 이야기할 수 있다.

만약 polynomial kernel 이라고 했을 때 : M= 2, γ = r = 1 and x,x′ ∈ R2

다음과 같은 커널이 있다면,

이렇게 표현이 가능하다. 즉 6 dimensional space의 feature space에 표현하는 것으로.. 생각할 수 있다는 것.
mercer kernel의 다른 예로는 sigmoid 커널이 있다고 한다.

근데 쓸 필요가 없다고 함.. ㅋ 뭐지
일반적으로 mercer kernel을 만드는 건 어렵지만 .. mercer kernel으로 또다른 것을 만들 수 있다고 함 다음과 같은 룰로..

14.2.4 Linear Kernels
커널로부터 feature vector를 얻는 거는 어려운데, 또한 mercer일때만 가능하고 feature vector로부터 kernel 얻는 거는 쉽다

걍 이렇게만 해주면 되는데 만약에 $\phi(x) = x$ 일 때를 linear kernel 이라고 부른다.

이건 original data가 원래 high demension이고 각 feature이 already informative 할 때 유용하다고 한다.
14.2.5 Matern Kernels
gaussian process regression에 흔히 쓰인다고 함 (15.2)


라구 한다.. 그냥 수식인데 쓰면 자꾸 오류나서 캡쳐해옴
14.2.6 String Kernels
kernel의 효과는 input이 structured object일 때 더 두드러진다고 함.
string kernel을 통해 두 개의 다른 길이의 시퀀스를 비교할 수 있는데, 두 string의 유사도를 자주 등장하는 substring의 개수 라고 가정해보자. string x를 x =usv 로 분해하고 $\phi_s(x)$를 substring s가 x에 등장하는 횟수라고 해 본다면 다음과 같은 kernel을 디자인할 수 있는데,

만약 $w_s >0$ 이고 A*가 alphabet A로부터 나올 수 있는 모든 string이라고 한다면 이건 Mercer kernel 이라고 한다.
만약 string 길이가 1 초과인 애들에 대해서 ws = 0이라고 한다면 이건 bag-of-characters kernel이다.
길이 제한을 k로 두면 k-spectrum kernel이다. ㅎㅎ
14.2.7 Pyramid match kernels
컴퓨터 비전에서 이미지의 feature vector에 대해서 bag of words representation을 만드는 것이 일반적인데 이 다양한 사이즈의 bag을 비교하는 방법이 일반적으로 pyramid match kernel 이다.

각 feature set은 multi-resolution histogram에 mapping되고 weighted histogram intersection으로 비교된다..
fineest spatial resolution을 찾기 위한 optimal bypartite match를 통해 similarity를 측정해서 다 합쳐서 사용한다고 한다.
이 Kerneldms mercer kernel임다..
14.2.8 Kernels derived from probabilistic generative models
만약 Feature vector에 대한 generative model을 가지고 있다고 생각한다면, $p(x|\theta)$, 이 model이 kernel function을 정의하도록 할 수 있는 여러가지 방법이 있다.
14.2.8.1 Probability product kernels
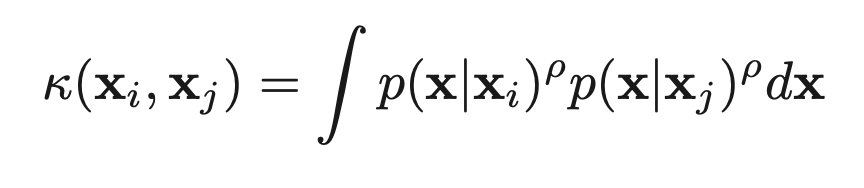
이렇게.. 다음과 같이 정의 되고 ρ > 0 일 때 p(x|xi)는 보통 p(x|hat(θ(xi)))에 의해서 근사되는데, hat(θ(xi))는 single data vector를 사용해서 추정되는 파라미터이다. 이 Kernel을 probability product kernel이라고 한다.
파라미터를 datapoint 하나를 가지고 추정한다는게 조금 이상해보일수도 있겠지만 두 datapoint의 similarity를 비교하는 것이라고 생각하면 납득이 간다.
14.2.8.2 Fisher kernels
generative model을 더 효과적으로 쓰는 방법은 Fisher kernel이다.

g는 gradient of the log likelihood 또는 score vector evaluated at the MLE and
F is the Fisher information matrix, which is essentially the Hessian.


theta는 모든 데이타로 핏됨.. 하나만있으면됨
g를 데이터에 대한 x의 gradient라고 생각한다면 the geometry encoded by the curvature of the likelihood function에 대해서 direction이 비슷하다면 비슷하다고 생각할 수 있는것..
후 끝났다... kernel은 좀 알아들을만해서 재밌는것같당 ㅎㅎ