
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- GAN
- Generative model
- iterm2환경설정
- GenerativeModel
- 프라이탁
- 캐나다 TD 한국인 직원 예약
- 캐나다 은행계좌 개설
- Normalizing flow
- 캐나다 TDBAnk
- MachineLearning
- 머신러닝
- 터미널꾸미기
- EATS
- 딥러닝
- pytorch
- DTW
- agnoster폰트
- 캐나다 은행 계좌 개설
- Docker
- 캐나다 TD 한국인 예약
- agnoster폰트꺠짐
- 캐나다 TD 예약
- 캐나다콘도렌트
- 콘도렌트
- 프라이탁 존버
- 캐나다월세
- agnoster폰트깨짐
- iterm2꾸미기
- Flow
- iterm2자동완성
- Today
- Total
TechNOTE
[논문리뷰] FlowSeq 본문
FlowSeq : Non-autoregressive Conditional Sequence Generation with Generative Flow
www.aclweb.org/anthology/D19-1437.pdf
Non-autoregressive Neural Machine Translation Model 중에 SOTA 성능을 낸 paper. Flow를 적용했다.
1. Introduction

기본적으로 Neural Machine Translation 에서는 .. target sentence에서 decoding을 진행할 때 이전 토큰에 대한 정보가 다음 토큰에 큰 영향을 미치기 때문에 autoregressive structure를 가지고 있다. 하지만 이는 토큰 하나하나를 생성해야 하기 때문에 시간이 상대적으로 오래 걸린다는 단점이 있다. (근데 speech 에서는 시퀀스가 워낙 길어서 엄청 비효율적인데.. nmt에서는 얼마나 오래 걸리는지 잘 몰라서 ㅋㅋ 궁금하다 시퀀스가 speech보다는 짧은 길이이지 않을까)
latent variable z 를 다음과 같이 도입해서 non autoregressive generation을 가능하게 한다고 한다.
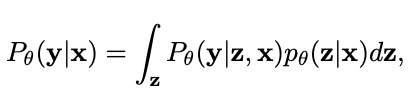
inference 과정에서는 다음과 같이, target sequence의 모든 token들을 독립적으로 sampling 할 수 있다고 가정하고 non-ar 방식으로 진행할 수 있는 것.

최종적으로 다음과 같은 loss를 이용하는 건데

다음 식에서 latent variable z를 marginalizing out 해버리는것은 불가능하당 ㅎㅎ 그래서 variational inference를 적용 , 다음과 같은 evidence lower bound를 adopt 함

2. Model structure

개인적으로는 그림이 직관적이지가 않다고 생각한다.. ;; ㅎㅎ ;; 일단 코드를 같이 봤는데,
2.1 Posterior Distribution

이렇게 생긴 posterior distribution을 어케 샘플링하나? 여기서는 posterior 분포가 normal 분포를 따라가는것을 보장하기 위해서 zero intialization과, posterior input으로 들어가는 y가 contextual representation을 배우는 것을 방해하지 않도록 token dropout 을 적용했다고 한다. 구현이 어떻게 되는건지 궁금해서 찾아봤다.

그.. 이 부분에서 본 것처럼 (원래 transformer decoder처럼) source encoding이 target encoder(이렇게 써서 헷갈리는데 사실 그냥 원래 transformer decoder라고 봐도 무방한것같음..) 에 들어가서 latent variable 을 모델링한다
2.3 Flow architecture for prior Distribution
그럼 여기서 중요한게 prior distribution 인데 ... prior distribution이 posterior를 잘 따라갈 수 있게 학습이 되어야지 inference 때도 training 때와 비슷한 결과를 줄 수 있으니까.. 그래서 이 prior distribution을 잘 형성하기 위해 Flow를 도입했다고 한다.

이 부분인데 구조는 Glow에서 차용하고 Multi-Scale Architecture 를 적용했다고 한다. 아마 source sentence 가 Multi head attention의 방식으로 Flow layer 에 들어가는 부분을 말하는 것 같다.
Training 때는 위에서 뽑은 target length 만큼의 latent variable (posterior distribution)이 Flow layer 를 타고 거꾸로 흐르면서 src encoding의 분포를 표현할 수 있도록 해준다..

Official code의 backward 파트 ㅎㅎ input 으로 z_posterior 를 받는다.

최종 log probability는 다음과 같이 결정이 된다.
그래서 이렇게 reconstruction loss와 kl divergence를 통해 학습이 되는데 non autoregressive 다 보니 여러 개의 decoding process 를 사용할 수 있다고 한다.
3. Decoding Process
3.1 Argmax Decoding
choosing the highest-probability latent sequence z

3.2 Noisy Parallel Decoding (NPD)
A more accurate approximation of decoding. draw samples from the latent space and compute the best output for each latent sequence. 결국 ar 모델을 바탕으로 ranking 을 매겨서 사용하게 되는거다 ㅎㅎ ;;
3.3 Importance Weighted Decoding
ranks these candidate sequences with K importance samples

4. Experiments
4.1 argmax decoding 쓴 거

4.2 Advanced Decoding Algorithm version

중요한 부분이 knowledge distillation을 적용했다고 하는데, tts와 같은 knowledge distillation이 아니라 pre-trained ar model 이 생성한 sample들을 이 non autoregressive model의 training data로 적용하는 것이다.
Contribution
- flow 를 sequence 2 sequence 에 적용한 첫 번째 approach ?
- non autoregressive 모델중에 SOTA
- flow 구조를 잘 쌓아올린게 novel한것 같다 ㅎㅎ 쉽지 않았을 텐데
Weakness
- 아직도 ar 성능에 못 미치고..
- 최적의 flow 구조라고 할 수 있을까?
NMT를 이렇게 해냈다는 것 자체가 신기하당 ㅎㅎ 굳굳 ..
'NLP' 카테고리의 다른 글
| Install KoNLP & Mecab (0) | 2022.04.12 |
|---|---|
| Aligning a corpus with Fastalign (0) | 2021.10.27 |
| [논문리뷰] Sparse Transformer (0) | 2020.11.20 |
