
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- agnoster폰트깨짐
- agnoster폰트
- 딥러닝
- iterm2꾸미기
- agnoster폰트꺠짐
- DTW
- 캐나다 은행 계좌 개설
- 캐나다 TDBAnk
- 캐나다 TD 한국인 예약
- EATS
- Flow
- 프라이탁
- 캐나다 은행계좌 개설
- 콘도렌트
- 머신러닝
- iterm2자동완성
- Generative model
- pytorch
- MachineLearning
- 캐나다콘도렌트
- 캐나다 TD 한국인 직원 예약
- iterm2환경설정
- 프라이탁 존버
- 캐나다 TD 예약
- Docker
- 터미널꾸미기
- GenerativeModel
- Normalizing flow
- 캐나다월세
- GAN
- Today
- Total
TechNOTE
[논문리뷰] Flow ++ 본문
Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design
Ho et al.
2019 ICML
Contribution
이 논문에서 주장하는, 이전 Flow model들의 세 가지 단점.
1. Dequantization을 위해 사용하는 uniform noise는 최적의 training loss, generalization 효과를 내는 선택이 아니다.
2. 일반적으로 사용되는, affine coupling flow들은 충분히 표현력이 강하지 않다.
3. coupling layer의 conditioning network에 사용되는 convolution layer들은 충분히 강력하지 않다.
그래서 이 논문에선 뭘 개선했나?
1. uniform dequantization -> variational flow-based dequantization
2. logistic mixture CDF coupling flows
3. self-attention in the conditioning networks of coupling layers.
Method
1. Dequantization Via Variational Inference?
CIFAR 10 이나 ImageNet과 같은 real-world dataset 은 continuous signal들을 discrete한 representation으로 quantize 해 놓은 것. 하지만 continous density model들을 discrete data에 fitting하는 것은.. 성능 저하를 일으킨다고 한다. 그래서 일반적인 해결책으로, dequantization을 통해 discrete data distribution을 continous distribution으로 바꾸어서 모델 학습에 사용한다고 한다.
1-1 Uniform Dequantization?
방법은 간단함.. 어떤 discrete data x 가 {0, 1, 2, ... , 255} 의 숫자로 표현이 가능하다고 할 때 각 x에 noise u ~ unif(0, 1) 를 더해주는 것.
$$y = x+ u $$
어떤 논문에(Theis et al. (2015))서 증명했는데.. uniformly dequantized data y를 가지고 continuous density model을 학습시키는 건 어떤 original discrete data 에 대한 모델인 Pmodel 의 log likelihood의 lower bound를 최대화 하는거라고 한다.
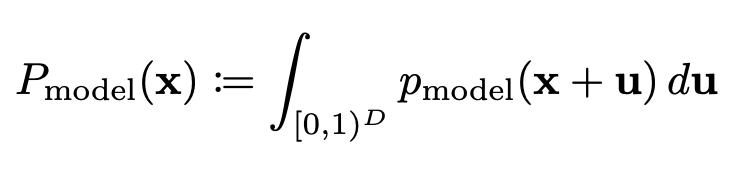
다음과 같다고 하면,
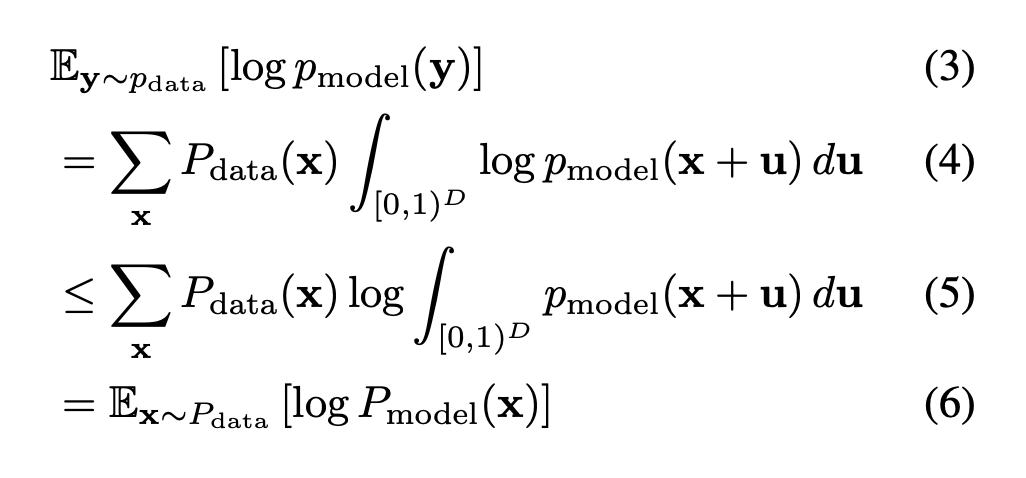
3번 식에서 p_data는 uniformly dequantized data distribution이므로 4번 식에서와 같이 uniform noise에 대한 적분과 discrete distribution인 Pdata(x)로 표현이 가능하다. Jensen's inequality덕에.. log는 concave이므로 4번 식에서 5번 식으로 log가 밖으로 빠져나올 수 있고, 그렇게 되면 안쪽의 적분은 위에 정의했던 P_model이 되므로 discrete data의 기댓값으로 표현이가능하다!
결과적으로, uniformly dequantized data로 continuous model의 log-likelihood를 최대화 하는 건 continous model degenerately collapsing을 일으키지 않는다! 왜냐하면 objective가 discrete model의 log-likelihood에 bounded above(유계) 되어있기 때문이다..!
1-2 Variational Dequantization?
위에 설명했던 .. uniform dequantization method가 효과적으로 collapsing to a degenerate mixture of point masses on discrete data 문제를 막았음에도, 결국 각 discrete point에 unit hypercube를 더하는 것이다. 이건 neural network density model같은 smooth function approximator들이 학습하기에는 어렵고, 부자연스러운데, 이 issue를 다루기 위해 이 저자들은 variational inference에 기초한 새로운 dequantization 방법을 제안한다!!
결국에는 D-dimensional discrete data를 continuous density model을 사용해서 모델링하는거에 관심이 있는건데 마찬가지로 log likelihood를 maximize해서 최적화를 할꺼다! 그런데, 여기서 새로운 dequantization noise distribution q(u|x) 를 도입하고 q를 approximate처럼 생각한다면, 다음과 같은 variational lower bound를 얻을 수 있다.
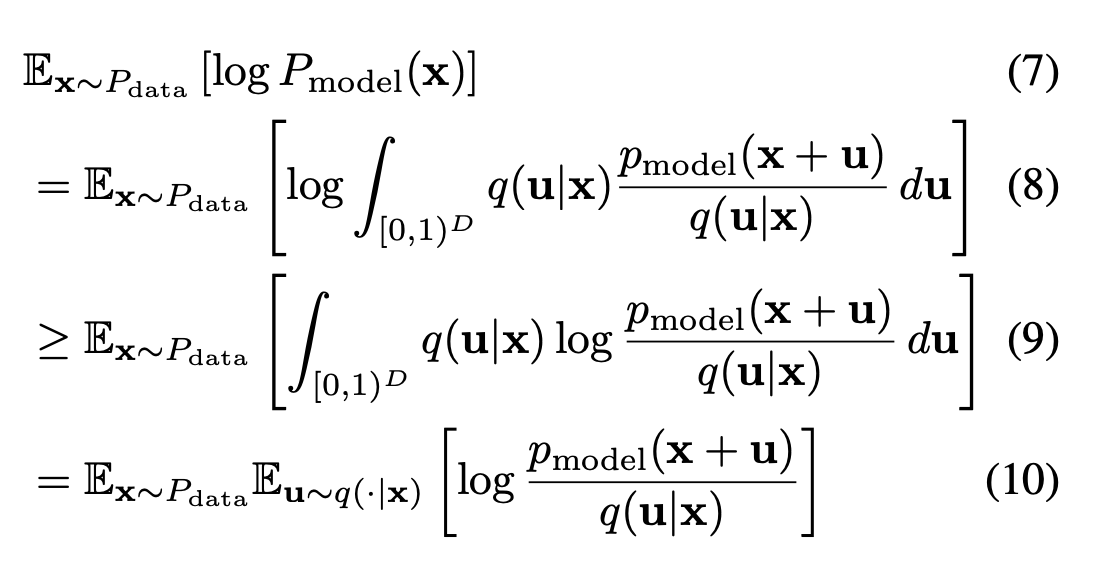
8에서 9로 넘어갈 때는 Jensen's inequality!
여기서 저자들은, q를 conditional flow based generative model로 표현하기로 했다.
$$u = q_x(\epsilon) \; where \; \epsilon \sim p(\epsilon) = N(\epsilon; 0, I)$$
이 경우에는
$$q(u|x) = p(q_x^{-1}(u)) * |\partial q_x^{-1}/\partial u| $$
로 표현이 가능하므로.. 최종 식은 다음과 같은 모양새가 된다
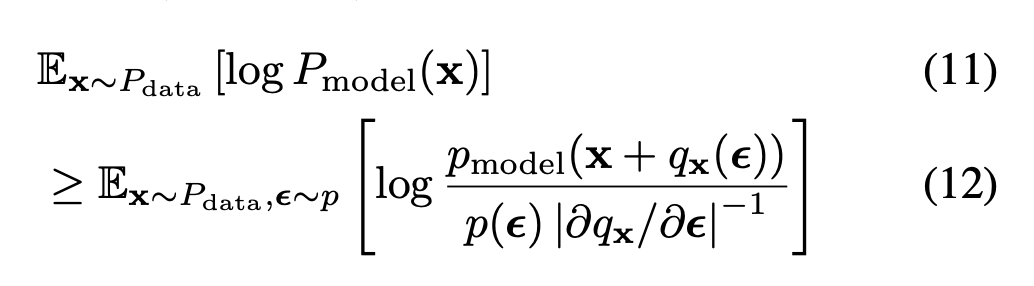
p와 q를 jointily maximize 한다.
주목할 만한 점은, 식 4~6의 lower bound for uniform dequantization은 이 variational lower bound의 special case 라는 것이다. 이 objective와 true expected log-likelihood의 차이는 정확히 다음과 같이 표현이 가능하다.
$$ E_{x\sim P_{data}}[D_{KL}(q(u|x)\| p_{model}(u|x))] $$
이를 통해 uniform한 q를 쓰는 것이 부자연스럽다고 추론할 수 있고, 표현력이 약한 q를 통해 잠재적인 손실이 존재할 것이라고 여길 수 있다. 하지만, expressive한 flow based q를 사용한다면 training, generalization loss를 낮출 수 있을 것이다..!
2. Improved Coupling Layer
2.1 Expressive Coupling Transformations with Continuous Mixture CDFs
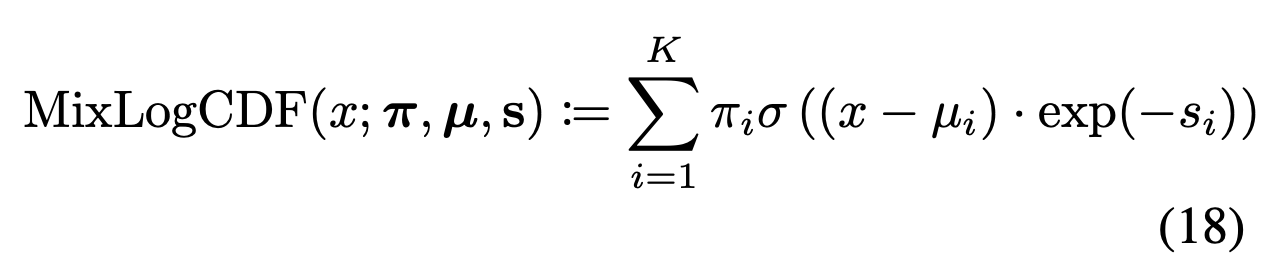
이전의 affine coupling layer를 바꾸어서 더 복잡한 분포를 표현하게 하는 방법이다..! Mixture of logistic 분포의 CDF 를 이용하는 것인데, 이를 이용하는 이유는 Mixture of Logistic 분포는 0, 1 사이에만 값이 존재하고 monotonic해서 invert 값을 구하기 쉽고, 또 미분값을 계산해보면 MoL의 Pdf 가 되기 때문에 계산이 쉽기 때문이다. 18번 식은 그냥 MoL CDF 의 정의. 시그마 기호는 sigmoid 함수를 의미한다.
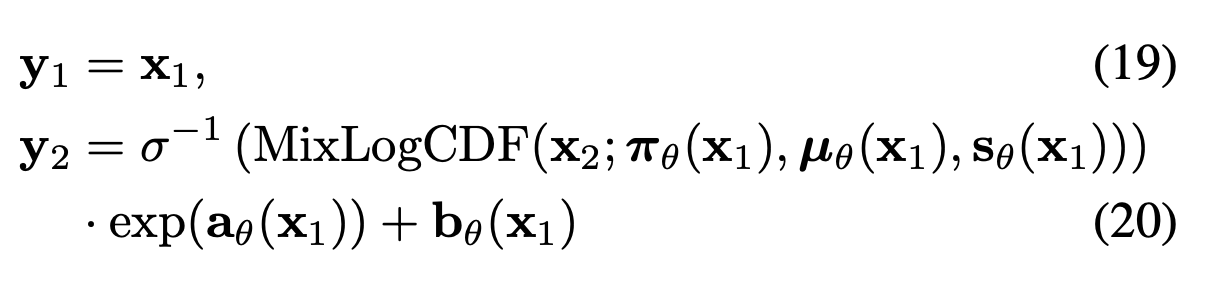
forward step은 다음과 같이 이루어진다. [x1, x2] = x 라고 했을 때, y1은 일반 affine coupling layer와 같이 x1이 그대로 전달되고, y2 부분에서 이전에 그냥 x2였던 부분을 MoL에 inverse sigmoid 곱해준 것을 사용한다! Inverse sigmoid는 이 coupling transformation의 inverse가 항상 존재한다는 것을 보증한다.
공식 깃헙에 이 부분을 보면 MixLogCDF의 inverse를 구하는 과정을 볼 수 있다.
2.2 Expressive Conditioning Architectures with Self-Attention
x2에 대한 Elementwise transformation의 표현력을 증가시키는것과 더불어, x1에 대한 conditioning의 표현력을 증가시키는 것도 성능에 중요한 요소임을 알아냈다고 한다..! 즉 elementwise transformation parameter들인 π, µ, s, a, b가 그 neural network의 expressiveness를 결정한다는 것! 저자들은 .. convolution과 multi-head self attention layer, gated residual network를 쌓아서 best result를 얻었다고 한다.

다음과 같은 구조 !
3. Experiments
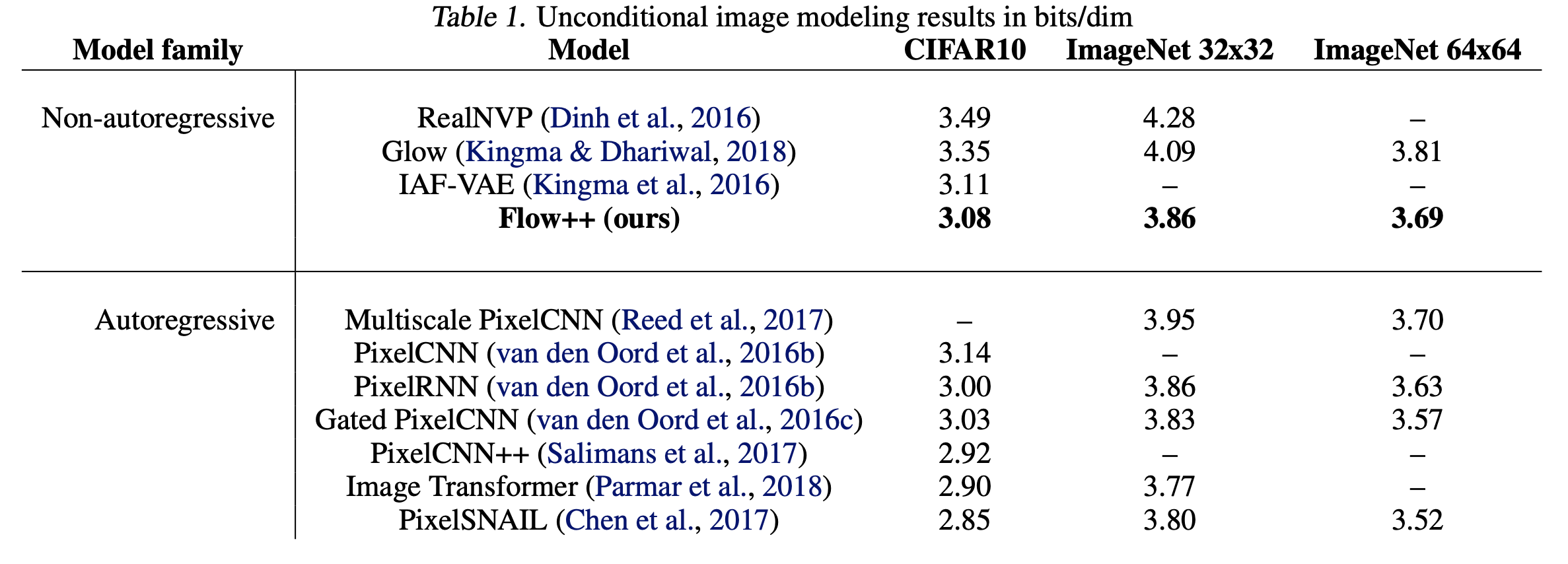
다른 .. Non autoregressive Model들보다는 성능이좋다구 한다.

이건 오늘 먹은 케이크이다. 논문리뷰와는 상관 없지만 너무 귀여워서 첨부하고 싶었다 ..
저 꽃 모양 초가 너무 귀엽당 ㅜ_ㅜ 흑
'딥러닝, 연구' 카테고리의 다른 글
| NVIDIA A100 사용하기 (0) | 2021.08.25 |
|---|---|
| [논문리뷰] You Only Look Once:Unified, Real-Time Object Detection (2) | 2021.05.27 |
| [GLOW] Affine Coupling Layer (0) | 2021.04.30 |
| Set python3 as default in ubuntu (0) | 2021.04.28 |
| [논문리뷰] Glow: Generative Flow with Invertible 1×1 Convolutions (2) | 2020.12.02 |


