
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- agnoster폰트깨짐
- 캐나다 TD 예약
- EATS
- 캐나다 TD 한국인 예약
- 콘도렌트
- agnoster폰트꺠짐
- GAN
- agnoster폰트
- 딥러닝
- Flow
- iterm2자동완성
- 머신러닝
- 프라이탁 존버
- Docker
- iterm2꾸미기
- 캐나다 은행 계좌 개설
- 프라이탁
- 캐나다콘도렌트
- GenerativeModel
- 캐나다 TD 한국인 직원 예약
- 캐나다월세
- 터미널꾸미기
- DTW
- iterm2환경설정
- 캐나다 은행계좌 개설
- Normalizing flow
- MachineLearning
- 캐나다 TDBAnk
- Generative model
- pytorch
- Today
- Total
TechNOTE
Mel spectrogram 설명 본문
음성 데이터를 raw data를 그대로 사용하면 파라미터가 너무 많아지기도 하고 데이터 용량이 너무 커지므로 보통 mel spectrogram을 많이 사용한다. 이게 뭔지 제대로 알아보도록 하자!
1. 음성파일 로드
sampling rate 24000 으로 구성된 wav 파일을 로드해 보면 다음과 같다.
sampling rate가 24000이라는 말은 1초에 음성 신호를 24000번 sampling 했다는 뜻이다.

2.STFT(Short Time Fourier Transform)
이 데이터에, STFT(Short Time Fourier Transform)를 해 준다. STFT란 뭘까?
그 전에 푸리에변환이 뭔지부터 보자..
푸리에 변환? (Fourier Transform)
www.youtube.com/watch?v=spUNpyF58BY&feature=youtu.be
여기에 진짜루 잘 나와있다... 이걸한번 보고오장
정리하자면 입력 신호를 다양한 주파수를 가지는 주기함수들로 분해하는 것.. 하지만 음성 신호에 그냥 fft를 사용해 버리면
각각의 주파수 성분이 언제 존재하는지는 알 수 없다!
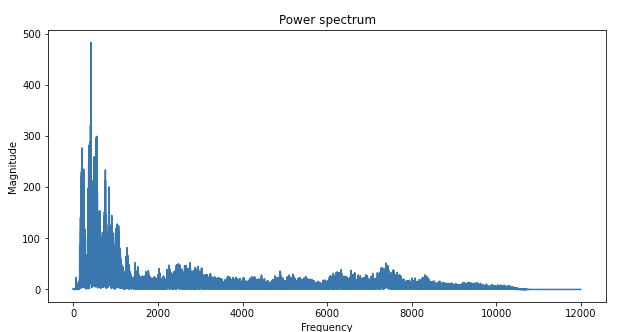
음성 신호에 푸리에 변환을 해 준것,, 음성이 어느 주파수의 어느 정도 magnitude를 가진 주기함수로 구성되어있다는건 알지만 시간정보가 손실되어서 ㅜ음성합성 & 인식에 이용하기에는 적절치 않다.
Short Time Fourier Transform ?
고렇다면 음성 데이터를 시간 단위로 짧게 쪼개서 FFT 를 해 주면 어떨까.
librosa에 존재하는 stft 를 사용해주면 쉽고 빠르게 할 수 있다.
librosa.org/doc/latest/generated/librosa.stft.html
librosa.stft — librosa 0.8.0 documentation
length of the windowed signal after padding with zeros. The number of rows in the STFT matrix D is (1 + n_fft/2). The default value, n_fft=2048 samples, corresponds to a physical duration of 93 milliseconds at a sample rate of 22050 Hz, i.e. the default sa
librosa.org
여기에서 argument 들이 무엇인지 잠깐 이야기해보자면,
1. n_fft : length of the windowed signal after padding with zeros.
한 번 fft를 해 줄 만큼의 sequence 길이
2. hop_length : window 간의 거리
3. win_length : window 길이..
이정도만 알면 되지 않을까..
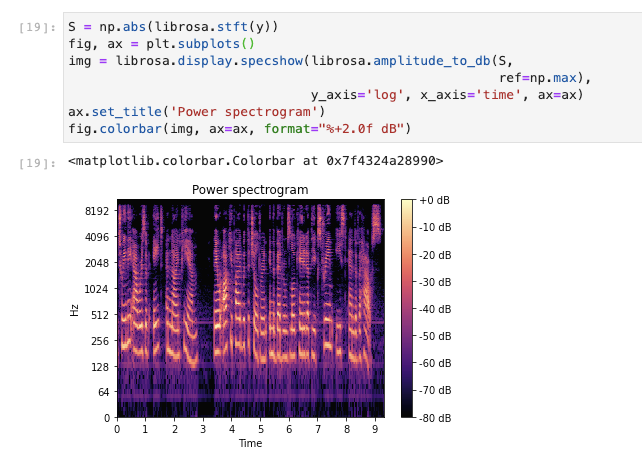
짠, 그리고 megnitude 를 dB로 바꿔준다. dB는 그냥 10*log(x) 해준 단위이다. 보면 각 시간당 주파수를 볼수있고 주파수가 얼마나 영향을 끼치는지 dB 단위로 plot된 것을 볼 수 있다.
3.Mel Spectrogram
사람들은 음성 신호를 인식할 때 주파수를 linear scale로 인식하는게 아니라고 한다. (생각해본다면 고주파로 간다고 서서히 안들리게 되는건 아니니까..) 그리고 낮은 주파수를 높은 주파수보다 더 예민하게 받아들인다고 한다. 즉 500 ~ 1000 Hz 가 바뀌는건 예민하게 인식하는데 10000Hz ~ 20000 Hz가 바뀌는 것은 잘 인식 못한다는 것.
그래서 이 주파수를 mel scale로 볼 수 있게 한것이다.
Mel(f) = 2595 log(1+f/700) 을 하면 mel scale 로 변환이 가능..
librosa.org/doc/latest/generated/librosa.filters.mel.html
librosa.filters.mel — librosa 0.8.0 documentation
© Copyright 2013--2020, librosa development team
librosa.org
이걸 쓰면 mel filter bank가 나온다.
그리고 이 filter bank를 아까 구했던 stft를 한 결과에 곱해주고 dB로 magnitude 를 바꿔 준다면 mel spectrogram 완성!
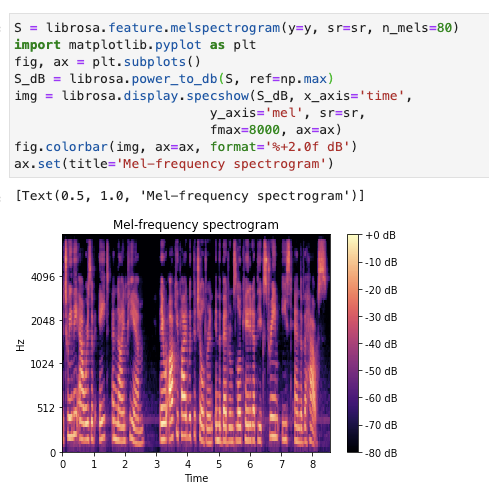
이걸 자동으로 해주는 mel_spectrogram 함수가 있으니.. 그걸 쓰도록 하자 ㅎ
'음성' 카테고리의 다른 글
| [논문리뷰] 간단한 EATS 리뷰 (0) | 2020.10.15 |
|---|
